Comparing and Searching: Three metrics
I focus in this text on a particular sort of textual analysis: what are called bag of words approaches, and one of their most important subsets, the vector space model of texts.
The key feature of a bag of words approach to text analysis is that it ignores the order of words in the original text. These two sentences clearly mean different things:
- “Not I, said the blind man, as he picked up his hammer and saw.”
- “And I saw, said the not-blind man, as he picked up his hammer.”
But they consist of the same core set of words. The key question in working with this kind of data is the following: what do similarities like that mean? You’ll sometimes encounter a curmudgeon who proudly declares that “literature is not data” before stomping off. This is obviously true. And, as in the concordances we constructed last week or the digital humanities literature that relies more heavily on tools from natural language processing, there are many ways to bring some of the syntactic elements of language into play.
But bag-of-words approaches have their own set of advantages: they make it possible to apply a diverse set of tools and approaches from throughout statistics, machine learning, and data visualization to texts in ways that can often reveal surprising insights. In fact, methods developed to work with non-textual data can often be fruitfully applied to textual data, and methods primarily used on textual data can be used on sources that are not texts. You may have an individual project using humanities data that is not textual. For example, we saw last week how Zipf’s law of word distributions applies to our city sizes dataset just as it applies to word counts. Almost all of the methods we’ll be looking at can be applied as easily, and sometimes as usefully, to other forms of humanities data. (Streets in a city, soldiers in an army, or bibliographic data.) But to do so requires transforming them into a useful model.
Three metrics
This section is one of the high points of the math in this book, because it describes three ways for creating word scores. We’re talking about three metrics. By metric I mean a score that represents something useful about a word. So far, we’ve used a number of basic properties inside ‘summarize’ and ‘mutate’ calls, but you’ve generally known what they do from the name: mean, median, sum, min, and so on. frequency, which we’ve looked at a bit lately, is slightly less transparent, but still easily understood; for words, it means the rate at which it’s used.
For working with counts, these aren’t always sufficient, and you need to resort to some specialized measures. This chapter introduces three of the most fundamental ones that are useful for applied research in digital humanities from the fields of information theory and information retrieval.
- TF-IDF: for search and OK for comparison
- Pointwise Mutual information: for comparing incidence rates.
- Dunning Log-likelihood: for making statistically valid comparisons.
TF-IDF is a more document-specific approach, that comes from the world of information retrieval; PMI comes more from the information science side of the world. And Dunning Log-Likelihood is something that gets close to issues around statistics.
TF-IDF: let’s build a search engine
Humanists use search engines constantly, but we don’t know how they work. You might think that’s OK: I drive a car with a variable transmission, but have absolutely no idea how it works. But the way that what you read is selected is more than a technical matter for a researcher; it’s at the core of the research enterprise. So to understand how bag-of-words approaches work, we’ll start by looking at one metric that is frequently used in search engines, something called TF-IDF.
A core problem of information retrieval is that, especially with multiword phrases, people don’t necessarily type what they want. They might, for example, search state of the union addresses for the words iraq america war. One of these words–“Iraq”– is much less common than the other two; but if you placed both into a search, you’d probably be overwhelmed by results for ‘war’ and America.
One solution might simply to be to say: rare words are the most informative, so we should overweight them. But by how much? And how should we define rareness?
There are several possible answers for this. The answer to this is based in an intuition related to Zipf’s law, about how heavily words are clustered in documents.
Here’s how to think about it. The most common words in State of the Union addresses are words like ‘of’, ‘by’, and ‘the’ that appear in virtually every State of the Union. The rarest words probably only appear in a single document. But what happens if we compare those two distributions to each other? We can use the n() function to count both words and documents, and make a comparison between the two.
To best see how this works, it’s good to have more than the 200 State of the Union addresses, so we’re going to break up each address into 2,000 word chunks, giving us about 1,000 documents of roughly equal length. The code below breaks this up into four steps to make it clearer what’s going on:
The red line shows how many documents each word would show up in if words were distributed randomly. They aren’t; words show up in chunky patterns. A paragraph that says “gold” once is more likely to use the word “gold” again than one that says “congress.”
This chunkiness, crucially, is something that differs between words. The word “becoming” doesn’t cluster within paragraphs; the word “soviet” does. TF-IDF exploits this pattern.
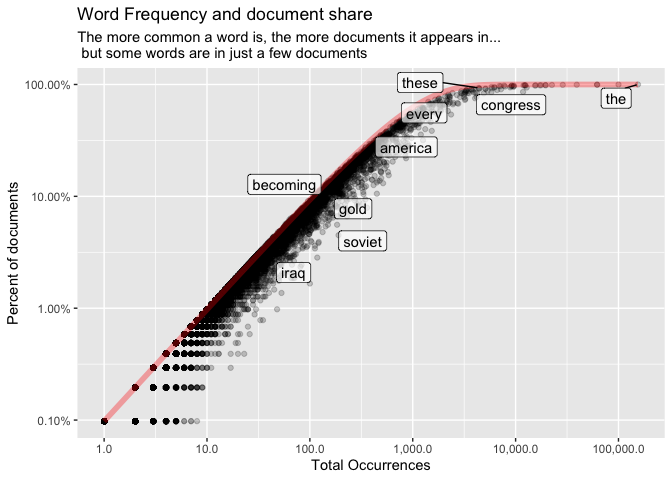
Rather than plotting on a log scale, TF-IDF uses a statistic called the ‘inverse document frequency.’ The alteration to the plot above is extremely minor. First, it calculates the inverse of the document frequency, so that a word appearing in one of a hundred documents gets a score of 100, not of 0.01; and then it takes the logarithm of this number.
This logarithm is an extremely useful weight. Since log(1) == 0, the weights for words that appear in every single document will be zero. That means that extremely common phrases (in this set, those much more common than ‘congress’) will be thrown out altogether.
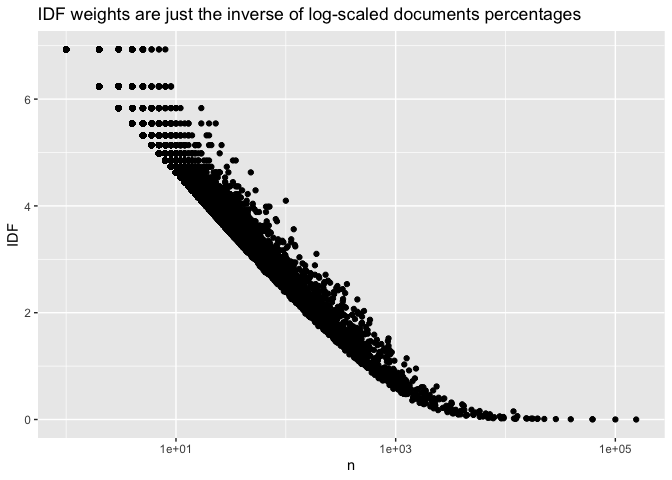
Create the word statistics field as above, and choose a number between 100 and 200, and look at the words that appear that many times. (Use filter(n == 100) to get the top 100 words.)
Look at which words have the highest IDF and the lowest IDF scores, looking also at the document counts for them. Does how clustered (i.e., how high the IDF score is) seem to indicate the specificity of the word? ::: {.cell hash=‘Bag-of-words_cache/json/unnamed-chunk-11_6e1edf69afe2741f31b6c52c2a972a45’}
:::
Finally, these IDF weights are multiplied by the term frequency.
This is one of the functions bundled into the module I’ve shared with you. You can run TF-IDF on any set of documents to see the distinguishing features. For instance, if we group by ‘president,’ we can see the terms that most distinguish each president.
So–say that we want to do a search for “Iraq”, “America”, and “War”. One way to build our own search engine is to make a table of those words, and join it to our already-created tf_idf weights. One of our tried-and-true summary operations can count up the scores.
Here are the first fifty words of the chunks that most strongly match our query.
Pointwise mutual information
TF-IDF is primarily designed for document retrieval; it has been used quite a bit, though, as a way to extract distinguishing words.
TF-IDF, though, is not a foolproof way to compare documents. It works well when the number of documents is relatively large (at least a couple dozen, say); but what if there are just 2 classes of documents that you want to compare? Or what if the documents are radically different sizes?
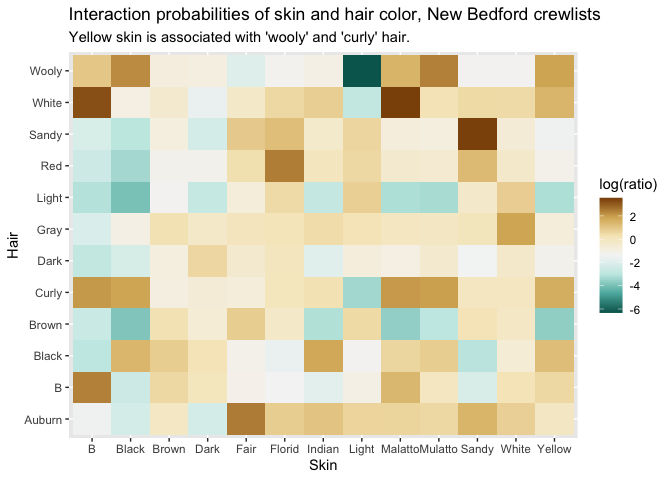
One very basic answer is a metric with an intimidating name, but a rather simple definition, called “pointwise mutual information.” I think of pointwise mutual information as simply a highfalutin way of something I think of as the “observed over expected ratio.” It calculates, simply, is how often an event occurs compared to how often you’d expect it to occur. We have already encountered a version of this statistic earlier: when we looked at the interactions of hair color and skin color among sailors in the New Bedford Customs Office dataset.
In fact, you may often find yourself coding a version of pointwise mutual information just in the course of exploring data.
PMI looks at the overall counts of documents and words to see how frequent each are: and then it estimates an expected rate of usage of each word based on how often it appears overall. For instance, if all presidents use the pronoun “I” at a rate of 1% of all words, you’d expect Barack Obama to also use it at that same rate. If he uses it at 1.5% instead, you could say that it’s 50% more common than expected.
Although this is built into the package functions, it’s simple enough to implement directly using functions we understand that it’s worth actually looking at as code.
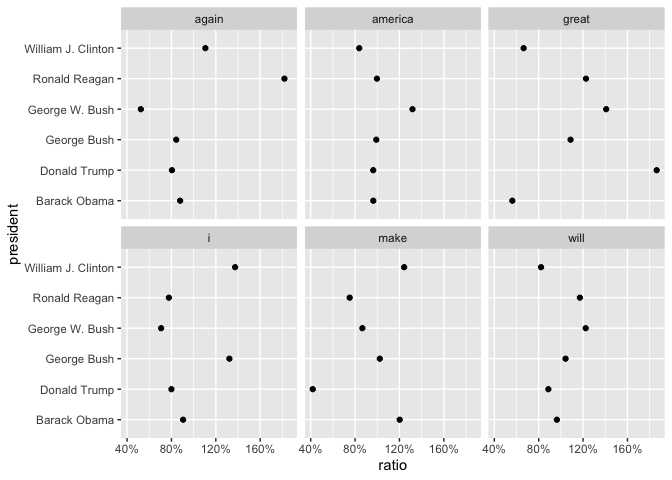
The visual problem is that we’re plotting a ratio on a linear scale on the x axis. But in reality, it often makes more sense to cast ratios in terms of a logarithmic scale, just as we did with word count ratios. If something is half as common in Barack Obama’s, that should be as far from “100%” as something that is twice as common.
Usually, we’d represent this by just using a log-transformation on the x-axis; but the log-transformation is so fundamental in this particular case that it’s actually built into the definition of pointwise mutual information. Formally, PMI is defined as the logarithm of that observed/expected ratio defined above. Since log(1) is zero, a negative PMI means that some combination is less common than you might expect, and a positive one that it’s more common than you’d expect. It’s up to you to decide if you’re working in a context where calling something ‘PMI’ and indicating the units as bits; or if you’re writing for a humanities audience and it make more sense to explicitly call this the ‘observed-expected ratio’ or some other circumlocution of your choosing.
If you’re plotting things, though, you can split the difference by using a logarithmic scale on the observed-expected value.
You can use PMI across wordcount matrices, but it also works on anything else where you can imagine an expected share of counts. We already talked about the observed and expected interactions of skin color and hair color in shipping datasets.
You can also look at word counts in a specific context: for instance, what words appear together more than you’d expect given their mutual rates of occurence? Using the lag function, we can build a list of bigrams and create a count table of how many times any two words appear together. Since each of these are events we can imagine a probability for, we can calculate PMI scores to see what words appear together in State of the Union addresses.
Some of these are obvious (‘per cent.’) But others are a little more interesting.
food
Dunning Log-Likelihood
While this kind of metric seems to work well for common words, it starts to break down when you get into rarer areas. If you sort by negative PMI on the president-wordcount matrix (try this on your own to see what it looks like), all the highest scores are for words used only by the president who spoke the fewest words in the corpus.
These kinds of errors–low-frequency words showing up everywhere on a list–are often a sign that you need to think statistically.
One useful comparison metric for wordcounts (and anyother count information) is a test known as Dunning log-likelihood. It expresses not just a descriptive statement about relative rates of a word, but a statistical statement about the chances that so big a gap might occur randomly. It bears a very close relationship to log-likelihood. In addition to calculating the observed-expected ratio for a word occurring in a corpus, you also calculate the observed-expected ratio for the word in all the works not in that corpus.
The sum of these quantities gives you a statistical score that represents a quantity of certainty that a different in texts isn’t by chance. Here’s some pseudo-code if you’re interested:
PMI tends to focus on extremely rare words. One way to think about this is in terms of how many times more often a word appears than you’d expect. Suppose we compare just two parties since 1948, Republicans and Democrats: suppose I say my goal to answer this question:
What words appear the most times more in Democratic Speeches and Republican ones, and vice versa?
There’s already an ambiguity here: what does “times more” mean? In plain English, this can mean two completely different things. Say R and D speeches are exactly the same overall length (I chose 1948 because both parties have about 190,000 words apiece). Suppose further “allotment” (to take a nice, rare, American history word) appears 6 times in R speeches and 12 times in D speeches. Do we want to say that it appears two times more (ie, use multiplication), or six more times (use addition)?
It turns out that neither of these simple operations works all that well. PMI is, roughly, the same as multiplication. In the abstract, multiplication probably sounds more appealing; but it actually catches extremely rare words. In our example set, here are the top words that distinguish R from D by multiplication, by occurences in R divided by occurrences in D. For example, “lobbyists” appears 20x more often in Democratic speeches than Republican ones.
By number of times, the Democrats are distinguished by stopwords–to, we, and ‘our’. We can assume that ‘the’ is probably a Republican word.
Is there any way to find words that are interesting on both counts?
I find it helpful to do this visually. Suppose we make a graph. We’ll put the addition score on the X axis, and the multiplication one on the Y axis, and make them both on a logarithmic scale. Every dot represents a word, as it scores on both of these things. Where do the words we’re talking about fall? It turns out they form two very distinct clusters: but there’s really a tradeoff here.
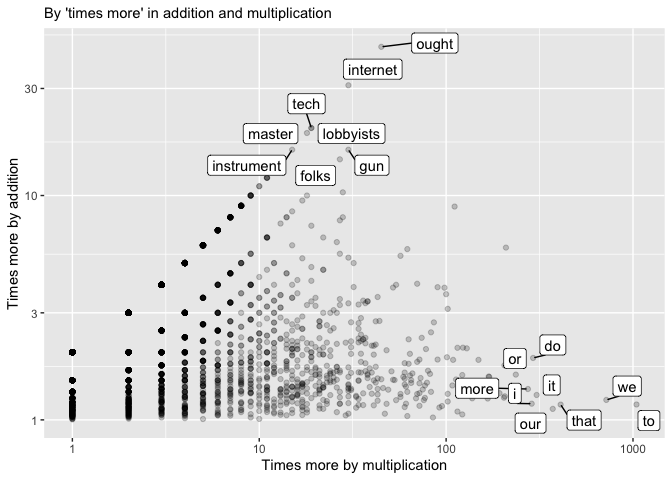
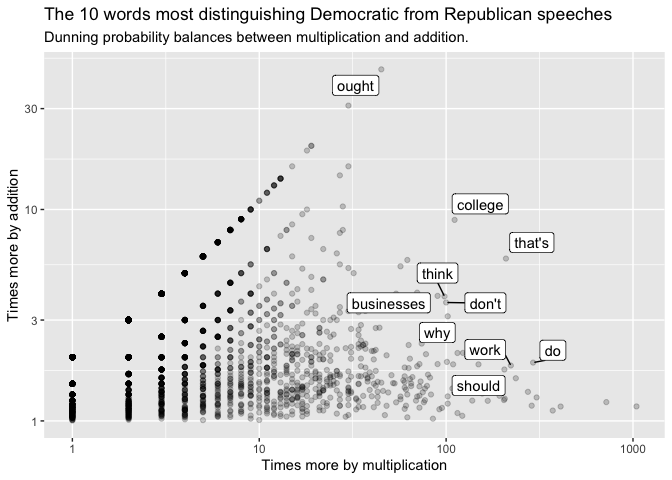
Dunning’s log-likelihood score provide a way of balancing between these two views. We use them the same way as the other summarize functions; by first grouping by documents (here ‘party’) and calling summarize_llr(word, n) where word is the quantity we’re counting and n is the count of fields.
If we redo our plot with the top Dunning scores, you can see that the top 15 words pulled out lie evenly distributed between our two metrics; Democratic language is now more clearly distinguished by its use of–say–the word ‘college.’
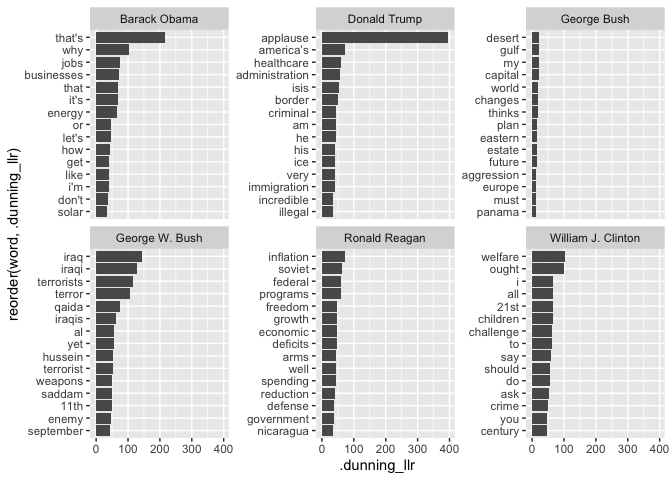
We can also do Dunning comparisons against a full corpus with multiple groups. Here, for example, is a way of thinking about the distinguishing words of multiple presidents State of the Union addresses.
These are not prohibitive problems; especially if you find some way to eliminate uncommon words. One way to do this, of course, is simply to eliminate words below a certain threshold. But there are more interesting ways. Just as we’ve been talking about how the definition of ‘document’ is flexible, the definition of “word” can be too. You could use stemming or one of the approaches discussed in the “Bag of Words” chapter. Or you can use merges to count something different than words.
For example, we can look at PMI across not words but sentiments. Here we’ll use a rather complicated list published in Saif M. Mohammad and Peter Turney. (2013), “Crowdsourcing a Word-Emotion Association Lexicon.” Computational Intelligence, 29(3): 436-465 that gives not just positive and negative, but a variety of different views. Essentially this is sort of like looking at words in greater numbers.
In this case, both the PMI and Dunning scores give comparable results, but the use of statistical certainty means that some things–like whether Jimmy Carter uses language of ‘disgust’–are quite suppressed. Here I calculate scores separately, and then use a pivot_longer operation to pull them together.
Note that there’s one new function here: scale is a function that brings multiple variables into a comparable scale–standard deviations from the mean–so that you can compare them. You’ll sometimes see references to ‘z-score’ in social science literature. That’s what scale does here.
First, we need to install the sentiment dictionaries themselves
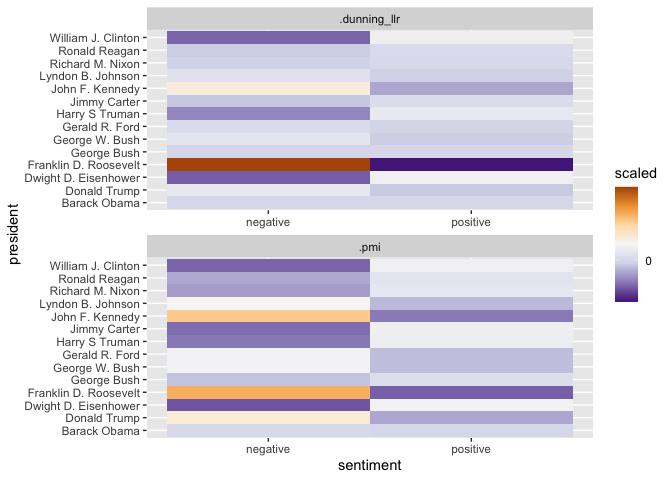
Another reason to use Dunning scores is that they offer a test of statistical significance; if you or your readers are worried about mistaking a random variation for a significance one, you should be sure to run them. Conversely, the reason to use PMI rather than log-likelihood is that it is actually a metric of magnitude, which is often closer to the phenomenon actually being described; especially if you use the actual observed/expected counts, rather that the log transformation.
So one strategy that can be useful is to use a significance test directly on the Dunning values. The function included in this package includes a column in the return value called (.dunning_significance); that indicates whether or not the difference at that location is statistically significant or not. (The calculations for doing this are slightly more complicated; they involve looking up the actual Dunning score in and translating it to a probability, and then applying a method called the Holm-Sidak correction for multiple comparisons because the raw probabilities don’t account for the fact that with wordcounts we make hundreds of comparisons.)
The chart below shows just the PMI values, but drops out all entries for which the Dunning scores indicate no statistical significance.
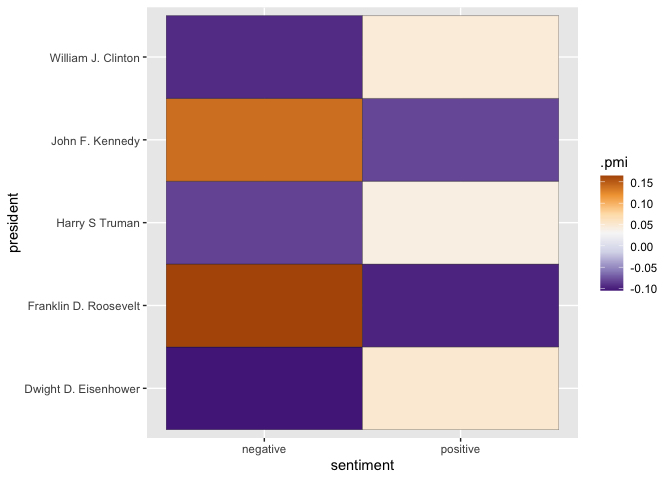
The term-document matrix
You can do a lot with purely tidy data, but another useful feature is something known as the “term-document matrix.” This is a data structure extremely similar to the ones that we have been building so far: in it, each row refers to a document, and each column describes a word.
This is not “tidy data” in Wickham’s sense, so it can be easily generated from it using the pivot_wider function in his tidyr package. Let’s investigate by looking at some state of the Union Addresses.
Here we re-use the read_tokens function we wrote in the previous chapter.
With State of the Union addresses, the most obvious definition of a document is a speech: we have that here in the frame “year”.
We also want to know how many times each word is used. You know how to do that: through a group_by and summarize function.
In a term-document matrix, the terms are the column names, and the values are the counts. To make this into a term-document matrix, we simply have to spread out the terms along these lines.
I’m going to use a few new features of the pivot_wider function here. “values_fill” says what to do if a word is not in one of the rows. For example, if Teddy Roosevelt never uses the word “television,” rather than filling in the corresponding cell with “NA”, we can make it “0”.
Note that I’m also renaming the ‘year’ column to ‘.year’ with a period.
That’s because ‘year’ is a word as well as a column, and in the wide form we can’t have columns capturing both meanings.
Usually, we’ve looked at data with many rows and few columns. Now we have one that is 229 columns rows by 29,000 columns. Those 10,000 columns are the distinct rows.
Later, we’ll work with these huge matrices. But for now, let’s set up a filter to make the frame a little more manageable.
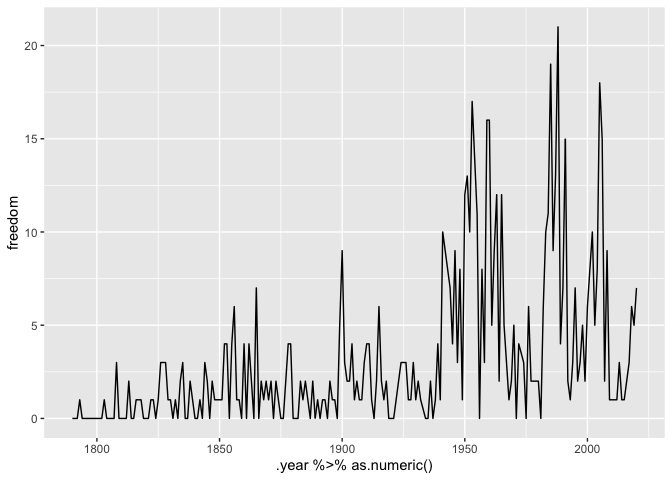
Consider some slices of the term-document matrix. These look sort of like what we’ve been doing before, but now the y-axis itself is called ‘freedom’, rather than “frequency” (or whatever).
This is important, because it means that each word is a kind of dimension, that can be used as a way to understand the texts.
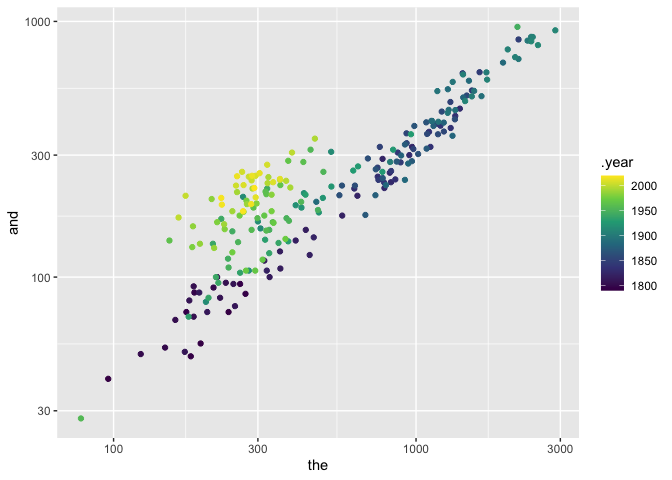
So for instance, we can plot “and” and “the” as two different axes. In general, the more that a book uses “and”, the more it uses “the”; but also years after 1950 are much lighter here because the pattern has broken down.
In this particular case, it mostly indicates something that I’ve mentioned before: that State of the Union addresses were mostly written before 1920 and mostly spoken after. The increased informality of spoken language gives them a different tone.
With this sort of data, it’s more useful to compare against a different set of texts.
But even in smaller regions, differences like this can be meaningful. Here’s an ggplot of usage of “and” and “for” in State of the Union addresses since 1981, looking at “and” and “for.”
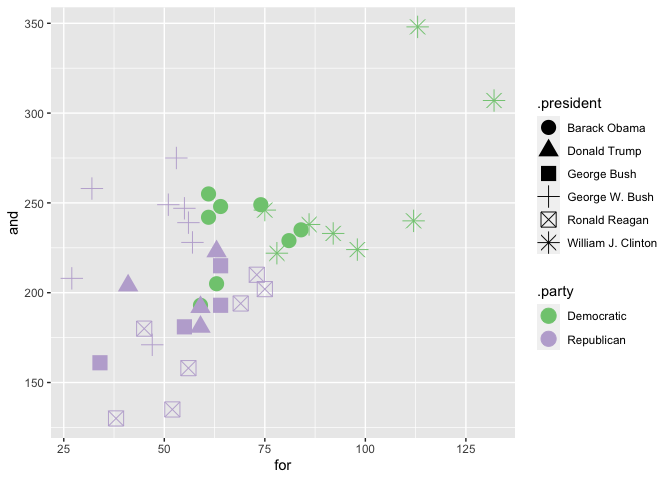
Note that we can get even more complicated: for instance, adding together lots of different words by using math in the aesthetic definition.
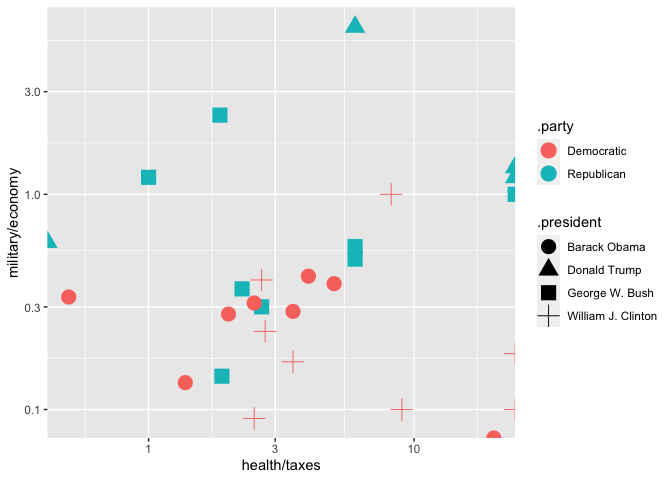
As a challenge–can you come up with a chart that accurately distinguishes between Democrats and Republicans?
There’s a big problem with this data: it’s not normalized. Bill Clinton used to talk, a lot, in his state of the union speeches. (We can prove this with a plot)
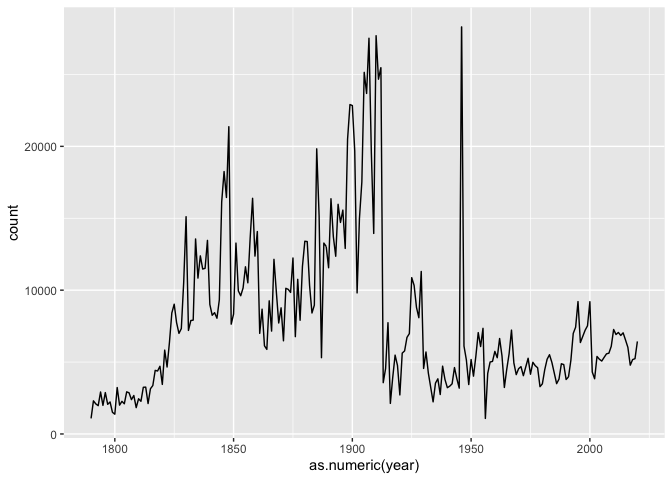
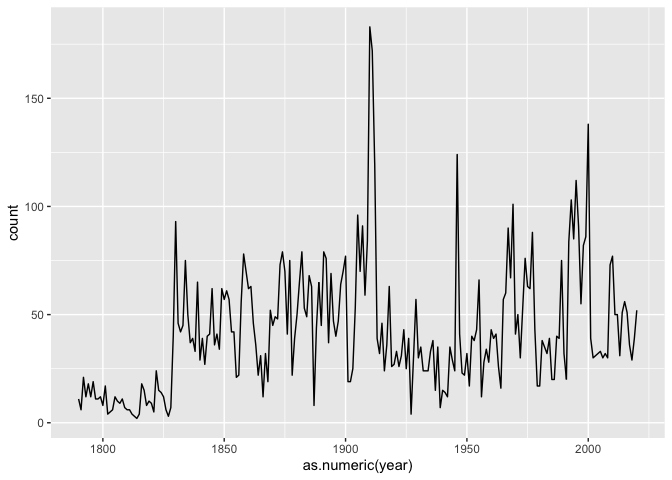
We can normalize these plots so that the term-document matrix gives the relative use per words of text. By setting ratio = count/sum(count) inside a mutute call, you get the percentage of the count.
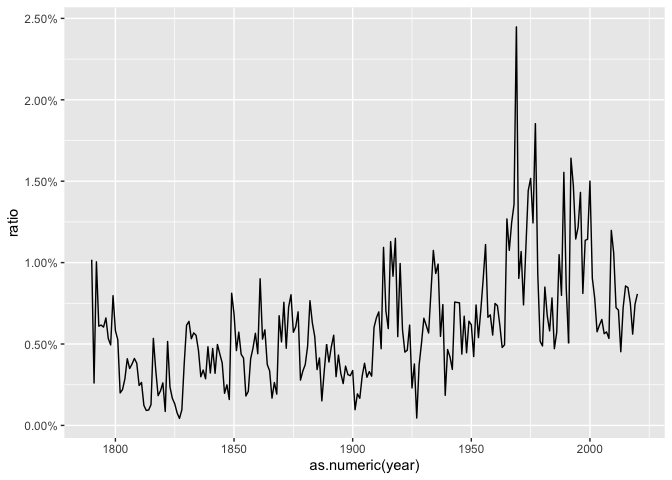
If you install the rgl library, you can look at some of these plots in 3 dimensions. This is confusing; 3d plotting is almost never a good idea. But by rotating a plot in 3-d space, you can begin to get a sense of what any of these efforts do.
Principal Components and dimensionality reduction
Principal Components are a way of finding a projection that maximizes variation. Instead of the actual dimensions, it finds the single strongest line through the high-dimensional space; and then the next; and then the next; and so forth.
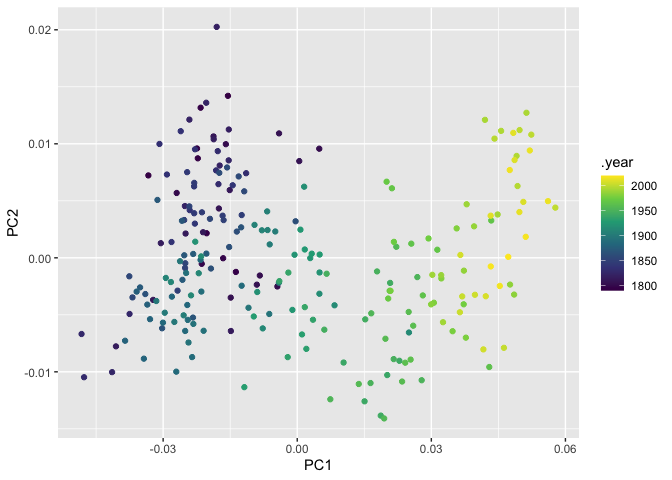
With extremely long time horizons, all separation usually happens along chronological lines. If we make the same plot, but colored by post-1980 president. Here you can see the the principal components are separating out Barack Obama and Bill Clinton separately from the other presidents.
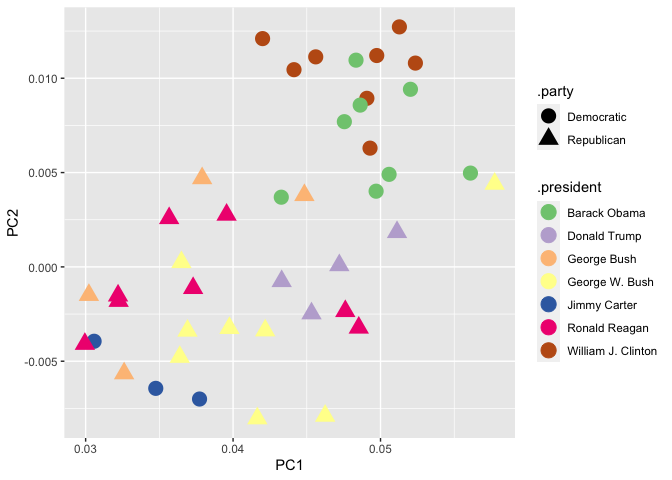
These models are created simply as weights against the word counts; we can extract those from the model by plucking the rotation element.
Definition:
pluck.pluckis a verb that works on non-data-frame element like models: it selects an element by its character name. In more traditional R,pluck(model, "rotation")might be written either asmodel[["rotation"]]or, more commonly,model$rotation.) Those methods are more concise in a line, but are awkward inside a chain.
The more modern speeches are characterized by using language like “we”, “our”, and “i”; the older ones by ‘the’, ‘of’, ‘which’, and ‘be’.
We can plot these too! It’s a little harder to read, but these begin to cluster around different types of vocabulary.
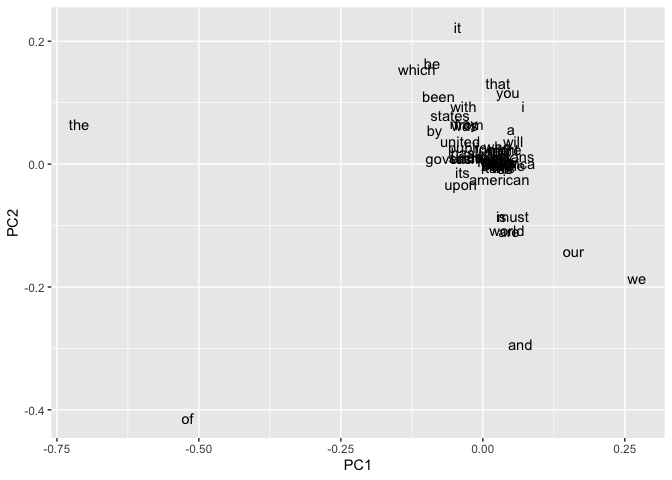
The “Word Space” that Michael describes is, in the broadest sense, related to this positioning of words together by document.@gavin_word_2018